SupremeTech’s Expertise in the Process of Performance Testing
10/12/2024
482
Table of Contents
In the previous article discussing The Importance of Performance Testing and SupremeTech’s Expertise, we understood the overview of performance testing and its significance for businesses. Let me introduce how SupremeTech manages performance and the process of performance testing to ensure our products are always ready to face real-world challenges.
At SupremeTech, product performance is not just a priority but a commitment. So how to do performance testing? Below is a detailed process of performance testing that we implement to ensure applications operate stably and efficiently under any usage conditions.
For more insights into Performance Testing, check out our blogs below:
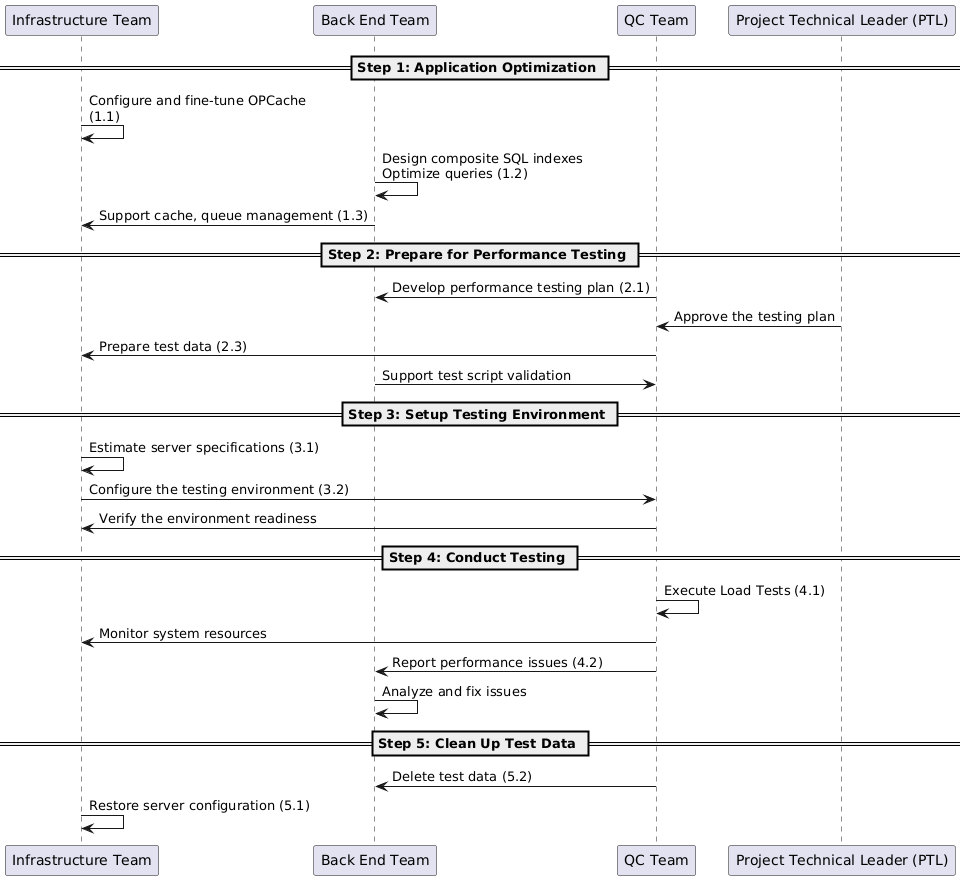
Step 1: Application Optimization
1.1 Optimizing OPCache
Infrastructure Team
- Responsible for configuring and fine-tuning OPCache on the server.
- Ensures that JIT (Just-In-Time) caching is enabled and that parameters align with system resources.
1.2 Database Optimization
Back End Team
- Designs composite indexes to enhance query speed.
- Rewrites or optimizes SQL queries to improve efficiency and reduce execution time.
- Analyzes common queries and data flows.
1.3 Optimizing Laravel During Deployment
Back End Team
- Considers activating Production Mode in Laravel.
- Executes the command php artisan optimize to optimize application configurations.
Infrastructure Team
- Manages caching for configurations, routes, and views.
- Supports the deployment and integration of queues or jobs on the server system.
Step 2: Preparing for Performance Testing
Collaboration among teams is crucial to ensure that every preparation step is accurate and ready for the performance testing process.
2.1 Developing a Plan and Initial Estimates
QC Team, Back-End Team
- Creates a detailed plan for each phase of performance testing.
- Proposes resource, time, and data requirements.
Project Technical Leader (PTL)
- Reviews and approves the testing plan.
- Coordinates appropriate resources based on preliminary estimates.
2.2 Security Checklist
Project Technical Leader (PTL)
- Develops a checklist of security factors to protect the system during testing.
QC Team, Back End Team
- Review the checklist to ensure completeness and accuracy.
2.3 Preparing Test Data
QC Team
- Creates accounts, test data, and detailed test scenarios.
- Writes test scripts to automate testing steps.
Back End Team
- Assists in building complex test data or necessary APIs.
- Reviews and tests scripts to ensure logic aligns with the actual system.
Step 3: Setting Up the Testing Environment
Coordination between the QC and Infrastructure teams is essential to ensure an optimized testing environment is ready for subsequent phases.
3.1 Estimating Server Specifications
Infrastructure Team
- Determines appropriate server configurations based on application needs and testing requirements.
- Provides optimal specifications based on available resources and product scale.
- Supplies information about physical resources and infrastructure to support testing.
3.2 Establishing the Testing Environment
Infrastructure Team
- Installs and configures virtual machines for performance testing.
- Adjusts server parameters (CPU, RAM, Disk I/O) to meet testing criteria.
QC Team
- Confirms that the environment is ready for testing based on established criteria.
3.3 Adjusting Parameters According to Testing Requirements
Infrastructure Team
- Modifies server configurations based on optimal parameters suggested after initial tests.
- Ensures configuration changes do not affect system stability.
Step 4: Conducting Tests
4.1 Performing Performance Tests
QC Team
- Executes load tests on APIs and key functionalities.
- Utilizes testing tools (JMeter, k6, Postman, etc.) to measure performance.
Infrastructure Team
- Supports environment management and monitors system resources during testing.
4.2 Reporting Results
QC Team, Infrastructure Team
- Compiles test results (response times, CPU load, RAM usage, etc.) from various tools.
- Compares results against established performance targets.
- Sends detailed reports to stakeholders (PTL, Backend Team).
4.3 Post-Test Optimization
Backend Team
- Analyzes test results and fixes bugs or optimizes source code and application logic.
Infrastructure Team
- Adjusts server configurations or optimizes system resources based on test outcomes.
QC Team
- Re-run tests after optimization to ensure improved performance is achieved.
- Compiles final test results and confirms with stakeholders.
Step 5: Clearing Test Data
5.1 Restoring Server Configuration to Initial State
Infrastructure Team
- Resets server configurations to their original state to reduce unnecessary resource consumption.
- Deletes or powers down virtual machines used during testing.
- Ensures no temporary configurations or unnecessary test environments remain in the system.
5.2 Removing All Test Data from Databases
QC Team
- Identifies test data that needs deletion to prevent junk data from affecting the live system.
Back End Team
- Safely deletes test data from the database while ensuring no production data is mistakenly removed.
- Verifies that the database is clean after deletion.
This process of performance testing enables SupremeTech to optimize each stage effectively, ensuring our products achieve optimal performance before delivery to partners. With our experienced workforce, we consistently prioritize product efficiency and quality.
Related Blog