Digital Out-Of-Home (OOH) Advertising Analytics in Japan
06/07/2023
1.1k
Table of Contents
While not the only player in the growing field of OOH analytics, Search provides advertising agencies and companies with concrete data about their audiences. This data can be used to quantify the value of their advertising efforts.
SupremeTech worked with Search to develop a web application and dashboard to display the data. The data is part of a cloud platform service that aggregates and visualizes data in real time. The data is displayed on the dashboard in real time in an easy-to-digest format.

The challenges of digital OOH advertising in Tokyo
The stereotypical image of a street in Tokyo contains all different types of signage and advertising. The sheer volume is enough to stimulate the senses, and digital billboards yell at you everywhere you go. This type of media is a form of out-of-home (OOH) advertising, which continues to evolve and proliferate the streets of urban Japan. When you see an advertisement playing you may not buy the product, but companies and advertising agencies want you as an audience. But how do they know for sure how big the audience is or if you are a part of it?
OOH advertising is one of the oldest forms of advertising, but nowadays it is one of the easiest platforms to monitor overall audience size. OOH is one of the only forms of advertising that adheres to a global standard for audience measurement. This standard makes it easy for companies to judge the value of their advertising.
Measuring a seemingly unmeasurable method of advertising
While OOH analytics is standard in places like Europe or North America, it has not seen the same level of success in Japan. Enter Search. While not the only player in the growing field of OOH analytics, Search provides advertising agencies and companies with concrete data about their audiences. This data can be used to quantify the value of their advertising efforts.
The data is used by digital billboard owners to promote their ad placement locations. Companies can use it to see the demographics that are viewing their ads. This allows these companies to fully understand and evaluate the reach of their advertising and media.
“Even those unfamiliar with OOH analytics could understand the meaning of each data point and how they are used.”
Visualize real-time data and make it user-friendly for OOH advertisers
SupremeTech worked with Search to develop a web application and dashboard to display the data. The data is part of a cloud platform service that aggregates and visualizes data in real time. The data is displayed on the dashboard in real time in an easy-to-digest format.
Within the dashboard, SupremeTech and Search created a report function that allows users to view the data based on the time each ad is aired, then users can create reports for their desired ads. This allows users to know exactly how many people are viewing a particular ad, in addition to the demographics of those viewers.
We worked with Search to define the various data points and how each should be presented. This was done carefully to make sure even those unfamiliar with OOH analytics could understand the meaning of each data point and how they are used. For example, the total number of VACs (Visibility Adjusted Contacts) changes rapidly over an hour or day. Every 15 seconds there could be a new influx of viewers. We implemented a graph that displays the total number of VACs in real time.
The audience measurement level for this service meets the highest level of VAC in the global standard audience measurement guidelines, formulated by the WOO (World Out of Home Organization). Search’s OOH analytics data provides users with the number of people who saw an ad with a quantifiable VAC number, in addition to the number who could have potentially seen it, or OTC, in addition to other useful metrics. This tool grants users the ability to evaluate their audience and the potential to grow that audience.

Web Development for a Dashboard with Real-Time Data
The first challenge in creating the dashboard was understanding the definitions of each data point and how they were calculated. We first had to meet with Search to better understand the terminology used for their OOH analytics. We also conducted our own research into the field of digital OOH advertising to better understand the field. Without a solid understanding of each feature, it would have been much more difficult to complete the project within the allotted three-month timeframe.
Then we had to ensure that all the data was presented in a way that was digestible and easy to understand. After all, this data is meaningless if we were the only people able to read it. Search provided us with a wireframe, and we created the UX/UI for an operational dashboard.
“When working with multiple vendors and cross-company teams, it is important to keep information channels open and flowing.”
Not everything went according to the wireframe, we changed some elements along the way after careful consideration and collaboration. For example, we tinkered with the text, data definitions, and graph visuals for the dashboard and report screens. Both SupremeTech and Search were open to new ideas that would make the product more valuable to the end users. The fluid communication between the teams made it easy to implement these changes.
The final step of the project was synchronizing the dashboard to the data provided by another vendor. There were delays in receiving some data, so we implemented our database using dummy data. When the camera data arrived, we were able to map it to the dummy data successfully.
When working with multiple vendors and cross-company teams, it is important to keep information channels open and flowing. Search’s cooperation and coordination kept the project moving forward despite minor setbacks along the way.

Digital OOH Advertising Analytics and Search in the Future
After 3 months of development, we completed the project. We created an accessible application for end users to visualize the data their media and advertisements were receiving. We coordinated with Search to synchronize the newly built application with the existing digital billboards scattered around Tokyo. Users can now log in and view the analyzed data in personal dashboards with ease. They can view the number of impressions their digital billboards and advertisements are getting in real time and access reports for their desired advertisements and digital billboards.
There are no longer questions surrounding how effective digital billboards and OOH advertisements can be. Now anyone can easily gain access to the data needed to ensure their marketing campaigns are successful.
This application has added tremendous value to digital billboard owners and the advertising agencies that air their content with them. This technology will undoubtedly continue to grow in popularity in Japan. Search aims to expand into new regions and areas in the country, and SupremeTech is grateful to have been a part of such a unique project.
Development System and Technologies
Below are the resources and technologies we use to deliver:
Details of entrustment: Design, Implementation, Testing, Data Migration, Release
Platform: Web app
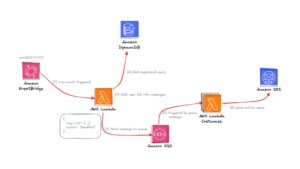
Infrastructure & Architecture: AWS
Development Front End: React.js
Development Back End: Java Spring
Get your custom software development services from SupremeTech!
SupremeTech offers comprehensive solutions to solve any technical challenges you have. We have the expertise to build a tailored software which streamlines your management and enhance customer experience.
Contact us now to take a step forward and discover how you can make your unique business idea come true with our technical expertises.
Brought to you by Search – SupremeTech team.
Related Blog