


Chức Năng Record Trong KATALON
19/12/2022
1.68k
Bạn là một Coder và muốn tái hiện kịch bản một cách nhanh nhất có thể? Hay bạn là một Tester mà chưa biết gì về lập trình cũng như rất khó có thể tiếp cận với Automation Testing? Thì ngay lúc này đây mình muốn chia sẻ đến bạn một tính năng rất hay trong Katalon đó là “Record”.
Để không dài dòng tốn thời gian, mình sẽ đi thẳng vào hướng dẫn luôn nhé!
Bước 1: Đầu tiên để có thể sử dụng được thì bạn hãy download và cài đặt theo link này nhé: https://www.katalon.com/download/
Bước 2: Xong, giờ bạn hãy mở Katalon lên và tùy chỉnh một vài thiết lập nho nhỏ nào.
- Vào Project>Settings

- Cửa sổ mới hiện ra, tiếp tục chọn: Execution. Tại đây ta sẽ tuỳ chỉnh cho “Default execution”, trường này cho phép ta chọn Browser mặc định khi ta chạy Test Cases. Ở đây mình set là “Chrome” nhé. Bạn cũng có thể chọn Firefox, IE, Safari tuỳ vào mục đích của bạn. Chọn xong thì Apply thôi.

Rồi đó, giờ bắt tay vào nha.
Tạo Project
Đầu tiên thì tất nhiên ta phải tạo Project mới rồi. Chọn vào File > New > Project.

Khi đó sẽ xuất hiện cửa sổ “New Project” như bên dưới. Ta sẽ điền tên project vào trường Name, tiếp tục vì ở đây mình hướng dẫn cho Web nên sẽ chọn “Web”. Tiếp đến chọn Location là nơi để chứa thư mục project này, có thể dùng mặc định có sẵn hoặc có thể tuỳ chỉnh chọn lại bằng cách click vào nút Browse… và chọn location bạn muốn. Khi đã hoàn tất xong, click vào nút OK để hoàn thành.

Sau đó sẽ tiếp tục hiện ra cửa sổ như bên dưới, bạn có thể bỏ qua bằng cách đóng lại.

Sau khi tạo thành công thì sẽ có những thư mục được tạo sẵn như ảnh dưới. Và ở bài viết lần này bạn chỉ cần quan tâm 2 thư mục mình đã khoanh đỏ là “Test Cases” và “Object Repository” nhé!

Record Web
Tại đây mình sẽ hướng dẫn bạn cách Record nhé! Đơn giản thôi, nó có nghĩa là Katalon sẽ ghi lại các thao tác mà bạn thực hiện trên web. Từ đó bạn sẽ lưu lại và tái sử dụng cho những lần sau.

Đầu tiên để ghi thì tất nhiên bạn cần bấm vào biểu tượng “Record Web” như ảnh bên trên. Sau đó sẽ hiển thị cửa sổ “Web Recorder” như bên dưới.
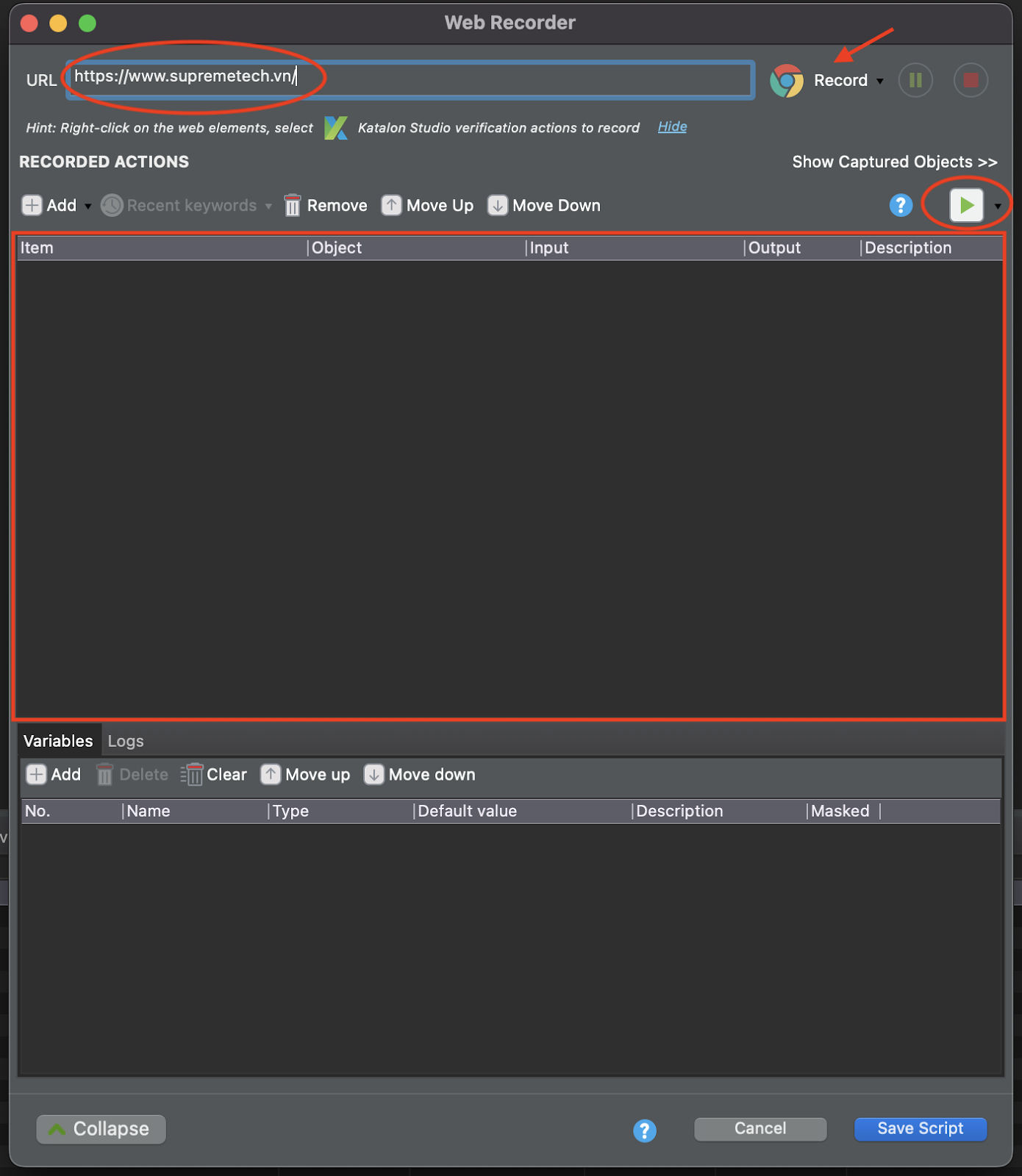
Những mục chính cần chú ý mình đã khoanh vùng đỏ ở ảnh trên:
- URL: là nơi bạn sẽ điền URL của web bạn sẽ truy cập.
- Browser: có thể click vào mũi tên bên cạnh để lựa chọn trình duyệt bạn sử dụng để chạy (Google Chrome, Firefox, IE, Safari, …)
- Vùng khoanh đỏ to rộng nhất thì đó chính là nơi sẽ ghi lại thao tác của bạn sau khi thực hiện trên web.
- Và cuối cùng sẽ là nút “Run all steps“, ở đây sau khi đã ghi lại các thao tác bạn có thể chạy thử với phần record đã được ghi lại.
Sau khi đã hài lòng với Test Case bạn mong muốn, hãy lưu lại TC này bằng cách click vào nút Save Script.
Dưới đây là màn hình kết quả sau khi mình đã thử ghi lại một số hành động thực hiện trên chính trang web https://www.supremetech.vn/

Sau đó sẽ có cửa sổ “Add Element to Object Repository” hiển thị:
- Vùng khoanh đỏ bên trái sẽ hiển thị ra cho bạn những element mà Katalon đã bắt được khi bạn thao tác.
- Vùng khoanh đỏ bên phải là nơi cho phép bạn chọn nơi lưu trữ element. Có thể chọn thư mục có sẵn hoặc có thể thêm mới bằng các click vào nút “New Folder” mình khoanh đỏ ở bên dưới.

Mình đã tự tạo mới folder có tên “test1” và nó đã được hiển thị ở vùng phía bên phải. Giờ mình sẽ lưu vào thư mục “test1” luôn nhé! Xong rồi thì hãy bấm OK thôi.

Lại thêm 1 cửa sổ khác hiện ra, bạn sẽ điền vào tên của Test Case. Tuỳ bạn đặt thôi, sao cho dễ phân biệt giữa những Test case. Ở đây mình sẽ điền vào “Test Case 1” và bấm OK.

Kiểm tra và Run lại phần đã Record
Đã tạo xong Test Case rồi đấy!
- Tại thư mục Test Cases bây giờ đã có thêm “Test Case 1” là cái mình đã đặt tên cho bộ test case ở phần trên đấy!
- Còn ở Object Repository đã có các element liên quan được lưu vào thư mục “test1” do mình tự tạo.
- Còn phần khoanh đỏ bên phải chính là phần hiển thị khi mình mở bộ “Test Case1” lên đấy.
- Và ta có thể Run test case này bằng cách bấm nút mình chỉ mũi tên màu đỏ bạn nha (có thể click nút mũi tên bên cạnh để chạy bằng trình duyệt khác, hoặc là click vào luôn thì sẽ chạy trình duyệt mặc định bạn đã chọn ở phần Setting).

Cảm ơn bạn đã theo dõi bài viết hôm nay của mình! Hi vọng bài viết này sẽ giúp bạn tiết kiệm được kha khá thời gian trong việc test.!
*(Bạn có thể theo dõi thêm *video bên dưới* mình thao tác cho tạo Test Case bằng Record để hiểu hơn nhé!)*