Castdice: The AI-powered English Learning App Leading the Tech Trend!
16/08/2023
1.14k
Table of Contents
Castdice is a groundbreaking English learning app designed specifically for Japanese students, boasting over 5000 downloads. It offers unique and innovative features to enhance student’s performance in university English entrance exams. Alongside essential functions like vocabulary search, word puzzles, and word assessments, Castdice’s standout feature lies in its use of Artificial Intelligence (AI) to create a Vocabulary Library containing words that have appeared in English entrance exams for all universities in Japan over the past 10 years.
With Castdice, students can access a vast array of vocabulary and study materials tailored to the specific requirements of university English exams. The app’s AI-powered features not only facilitate effective learning but also ensure that students are well-prepared and confident in tackling their English entrance tests.

Castdice – The Ultimate Solution for Japanese Students’ University English Entrance Exams
Preparing for university entrance exams is a pressing concern for every high school student in Japan. Especially, the importance of English proficiency is increasingly recognized in the country. Students must thoroughly prepare for the English exam to secure admission to their desired universities. Searching for past English exam papers from various universities to practice with has become a common practice, but it is time-consuming and challenging.
In response to this urgent need, Castdice was born to address the crucial issue students face: gathering vocabulary words that appeared in the last 10 years’ exam papers. The app offers a comprehensive vocabulary library based on extensive real-exam data from universities and high schools across Japan, making it easy for students to access essential and practical words.
With Castdice, students no longer struggle to find and study vocabulary on their own. The app provides a modern, up-to-date, and indispensable solution for every student in Japan. It has become a reliable companion for students, helping them boost their English proficiency, excel at exams, and pave the way for success in their academic and professional futures.
Our Challenge: Transforming Diverse Data into Vocabulary through AI
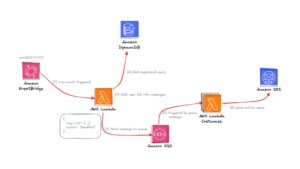
We faced a significant challenge when dealing with the diverse data, which was not well-organized and existed in various formats like PDFs and scanned images. To make this data usable, we had to convert it into a dictionary-like format for effective processing.
The process to solve this Challenge:
Data Collection: The first step involved collecting all the vocabulary from large public test datasets. The team utilized data mining techniques to extract relevant information from English test sets used by Japanese universities.
Data Extraction: The team employed Optical Character Recognition (OCR) technology for PDF data to convert the scanned text into editable and searchable text. This step was crucial to extract text from image-based documents.
Text Processing: Once the data was extracted, the team used natural language processing tools, such as the Natural Language Toolkit (NLTK), to split and tokenize the text. This allowed them to separate individual words and prepare them for further analysis.
Mapping and Ranking: The team mapped each word with a dictionary and included a ranking system. This helped categorize and prioritize the vocabulary based on its relevance and frequency in the English test sets.
Pronunciation Integration: To enhance the learning experience, Castdice integrated Text-to-Speech technology, creating accurate pronunciations for each word. This feature proved beneficial for users to improve their speaking and listening skills.
Database Creation: Finally, the team compiled all the processed text data into a structured database. This database served as the foundation for the AI-powered apps, allowing users to browse and create different workbooks tailored to their specific needs and target various universities and levels.
Result:
By overcoming the challenges and implementing the above process, Castdice successfully developed two mobile apps integrated with the Flutter framework. These apps utilized the AI-driven Vocabulary Library, empowering users to access and use a comprehensive vocabulary and study materials collection.
Despite the time and resource constraints, our team’s innovative approach and use of AI technology led to the creation of a powerful and effective language-learning platform for students in Japan. Castdice’s commitment to solving this problem with ingenuity has transformed how students prepare for English exams, providing them with a cutting-edge tool for language learning and exam preparation.
Highlights of Castdice’s Intelligent Vocabulary Library feature
In addition to the typical features of an AI-based English learning app, such as vocabulary search, quizzes, and vocabulary learning, Castdice boasts a remarkable and delightful feature known as the Intelligent Vocabulary Library. This smart library sets itself apart and leaves a lasting impression on all users for several compelling reasons.
Diverse Collection of Thousands of Words: The Intelligent Vocabulary Library is built upon a vast database of English exam questions from all universities in Japan over the past decade. This ensures that the library is not only extensive but also contains practical words and commonly used in real-life exam scenarios.
Continuous Data Updates: Despite being launched in 2021, the Intelligent Vocabulary Library of Castdice is consistently updated with the latest English entrance exam questions from Japanese universities up to the present. This allows students to access the most current and relevant vocabulary, effectively preparing them for their upcoming exams.
Targeted Learning Approach: Powered by Artificial Intelligence (AI), Castdice utilizes data from various English exam papers to identify the most important and frequently used words. Students are exposed to high-priority vocabulary likely to appear in crucial English exams, enabling them to focus on mastering the most essential words and significantly improving their test scores.
Personalized Learning Experience: The Intelligent Vocabulary Library allows for personalized learning for each individual student. AI assesses each user’s proficiency level and learning needs, providing tailored study materials to achieve the highest efficiency in English language proficiency.
Thanks to these remarkable advantages, Castdice’s Intelligent Vocabulary Library stands out as a prominent feature. It empowers users to efficiently access and confidently apply their vocabulary knowledge during the rigorous English entrance exams for Japanese universities.
Elevate Your English Proficiency with Castdice English Learning App
Castdice has significantly and comprehensively improved students’ English learning in a multifaceted manner. All students who have used Castdice for their studies have experienced positive outcomes and noticeable benefits from vocabulary learning through this app:
- Excelling in English Entrance Exams: Over 90% of surveyed students have seen a remarkable increase in their exam scores since using Castdice. The extensive vocabulary library, curated from the past 10 years’ exams, enables students to effortlessly encounter words commonly found in test papers and excel in their exams.
- Learning more vocabulary and grammar: The AI English Learning app integrates various vocabulary learning methods, from traditional to modern, and employs intelligent progress tracking for each individual. This feature helps learners memorize vocabulary more effectively.
- Improving pronunciation and listening comprehension: Castdice provides English listening vocabulary, allowing students to practice listening and pronunciation consistently. This enhances their listening skills and pronunciation, increasing confidence in communication and understanding English dialogues.
- Enhancing interactivity and engagement: The app uses interactive learning methods and fun quizzes, fostering active student participation and motivating them to continue studying English with enthusiasm.
- Saving time and flexibility: The English learning app allows students to study anytime, anywhere, through their mobile phones or tablets. This flexibility empowers students to manage their study time conveniently.
Development systems and technologies
Below are the resources and technologies we use to develop Castdice App:
- Details of entrustment: Design, Implementation, Testing, Migration, Maintenance & Operation
- Platform: Mobile App
- Mobile architecture: Firebase, Flutter
- Server architecture: Python, GCP
Castdice – Outstanding Success with 5000+ Downloads!
SupremeTech accomplished the creation of a data mining module and an AI-powered vocabulary database. They also developed two mobile apps optimized with a single Flutter source code as part of their achievements. The remarkable success has garnered over 5000 downloads, affirming our reputation and capturing the interest of a wide user base. If you are considering developing a groundbreaking and efficient learning app, explore the proud accomplishments of Castdice!
Related Blog