
Automate Your Git Workflow with Git Hooks for Efficiency
24/12/2024
1.93k
Have you ever wondered how you can make your Git workflow smarter and more efficient? What if repetitive tasks like validating commit messages, enforcing branch naming conventions, or preventing sensitive data leaks could happen automatically? Enter Git Hooks—a powerful feature in Git that enables automation at every step of your development process.
If you’ve worked with webhooks, the concept of Git Hooks might already feel familiar. Like API events trigger webhooks, Git Hooks are scripts triggered by Git actions such as committing, pushing, or merging. These hooks allow developers to automate tasks, enforce standards, and improve the overall quality of their Git workflows.
By integrating Git Hooks into your project, you can gain numerous benefits, including clearer commit histories, fewer human errors, and smoother team collaboration. Developers can also define custom rules tailored to their Git flow, ensuring consistency and boosting productivity.
In this SupremeTech blog, I, Đang Đo Quang Bao, will introduce you to Git Hooks, explain how they work, and guide you through implementing them to transform your Git workflow. Let’s dive in!
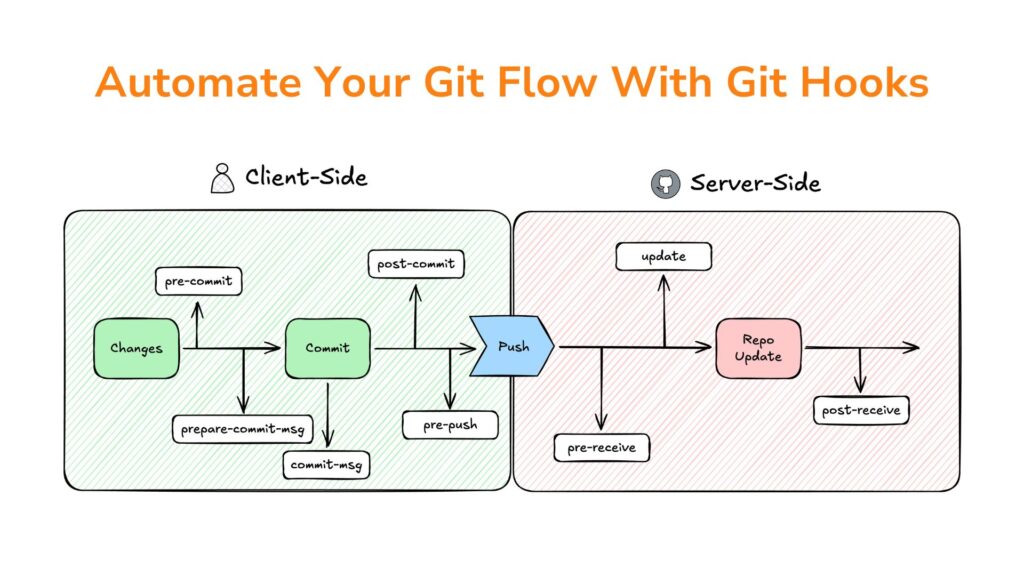
What Are Git Hooks?
Git Hooks are customizable scripts that automatically execute when specific events occur in a Git repository. These events might include committing code, pushing changes, or merging branches. By leveraging Git Hooks, you can tailor Git’s behavior to your project’s requirements, automate repetitive tasks, and reduce the likelihood of human errors.
Imagine validating commit messages, running tests before a push, or preventing large file uploads—all without manual intervention. Git Hooks makes this possible, enabling developers to integrate useful automation directly into their workflows.
Type of Git Hooks
Git Hooks come in two main categories, each serving distinct purposes:
Client-Side Hooks
These hooks run on the user’s local machine and are triggered by actions like committing or pushing changes. They are perfect for automating tasks like linting, testing, or enforcing commit message standards.
- Examples:
- pre-commit: Runs before a commit is finalized.
- pre-push: Executes before pushing changes to a remote repository.
- post-merge: Triggers after merging branches.
Server-Side Hooks
These hooks operate on the server hosting the repository and are used to enforce project-wide policies. They are ideal for ensuring consistent workflows across teams by validating changes before they’re accepted into the central repository.
- Examples:
- pre-receive: Runs before changes are accepted by the remote repository.
- update: Executes when a branch or tag is updated on the server.
My Journey to Git Hooks
When I was working on personal projects, Git management was fairly straightforward. There were no complex workflows, and mistakes were easy to spot and fix. However, everything changed when I joined SupremeTech and started collaborating on larger projects. Adhering to established Git flows across a team introduced new challenges. Minor missteps—like inconsistent commit messages, improper branch naming, accidental force pushes, or forgetting to run unit tests—quickly led to inefficiencies and avoidable errors.
That’s when I discovered the power of Git Hooks. By combining client-side Git Hooks with tools like Husky, ESLint, Jest, and commitlint, I could automate and streamline our Git processes. Some of the tasks I automated include:
- Enforcing consistent commit message formats.
- Validating branch naming conventions.
- Automating testing and linting.
- Preventing accidental force pushes and large file uploads.
- Monitoring and blocking sensitive data in commits.
This level of automation was a game-changer. It improved productivity, reduced human errors, and allowed developers to focus on their core tasks while Git Hooks quietly enforced the rules in the background. It transformed Git from a version control tool into a seamless system for maintaining best practices.
Getting Started with Git Hooks
Setting up Git Hooks manually can be dull, especially in team environments where consistency is critical. Tools like Husky simplify the process, allowing you to manage Git Hooks and integrate them into your workflows easily. By leveraging Husky, you can unlock the full potential of Git Hooks with minimal setup effort.
I’ll use Bun as the JavaScript runtime and package manager in this example. If you’re using npm or yarn, replace Bun-specific commands with their equivalents.
Setup Steps
1. Initialize Git: Start by initializing a Git repository if one doesn’t already exist
git init
2. Install Husky: Use Bun to add Husky as a development dependency
bun add -D husky
3. Enable Husky Hooks: Initialize Husky to set up Git Hooks for your project
bunx husky init
4. Verify the Setup: At this point, a folder named .husky will be created, which already includes a sample of pre-commit hook. With this, the setup for Git Hooks is complete. Now, let’s customize it to optimize some simple processes.

Examples of Git Hook Automation
Git Hooks empowers you to automate tedious yet essential tasks and enforce team-wide best practices. Below are four practical examples of how you can leverage Git Hooks to improve your workflow:
Commit Message Validation
Ensuring consistent and clear commit messages improves collaboration and makes Git history easier to understand. For example, enforce the following format:
pbi-203 – refactor – [description…]
[task-name] – [scope] – [changes]
Setup:
- Install Commitlint:
bun add -D husky @commitlint/{config-conventional,cli}
- Configure rules in commitlint.config.cjs:
module.exports = {
rules: {
'task-name-format': [2, 'always', /^pbi-\d+ -/],
'scope-type-format': [2, 'always', /-\s(refactor|fix|feat|docs|test|chore|style)\s-\s[[^\]]+\]$/]
},
plugins: [
{
rules: {
'task-name-format': ({ raw }) => {
const regex = /^pbi-\d+ -/;
return [regex.test(raw),
`❌ Commit message must start with "pbi-<number> -". Example: "pbi-1234 - refactor - [optimize function]"`
];
},
'scope-type-format': ({ raw}) => {
const regex = /-\s(refactor|fix|feat|docs|test|chore|style)\s-\s[[^\]]+\]$/;
return [regex.test(raw),
`❌ Commit message must include a valid scope and description. Example: "pbi-1234 - refactor - [optimize function]".
\nValid scopes: refactor, fix, feat, docs, test, chore, style`
];
}
}
}
]
}
- Add Commitlint to the commit-msg hook:
echo "bunx commitlint --edit \$1" >> .husky/commit-msg
- With this, we have completed the commit message validation setup. Now, let’s test it to see how it works.
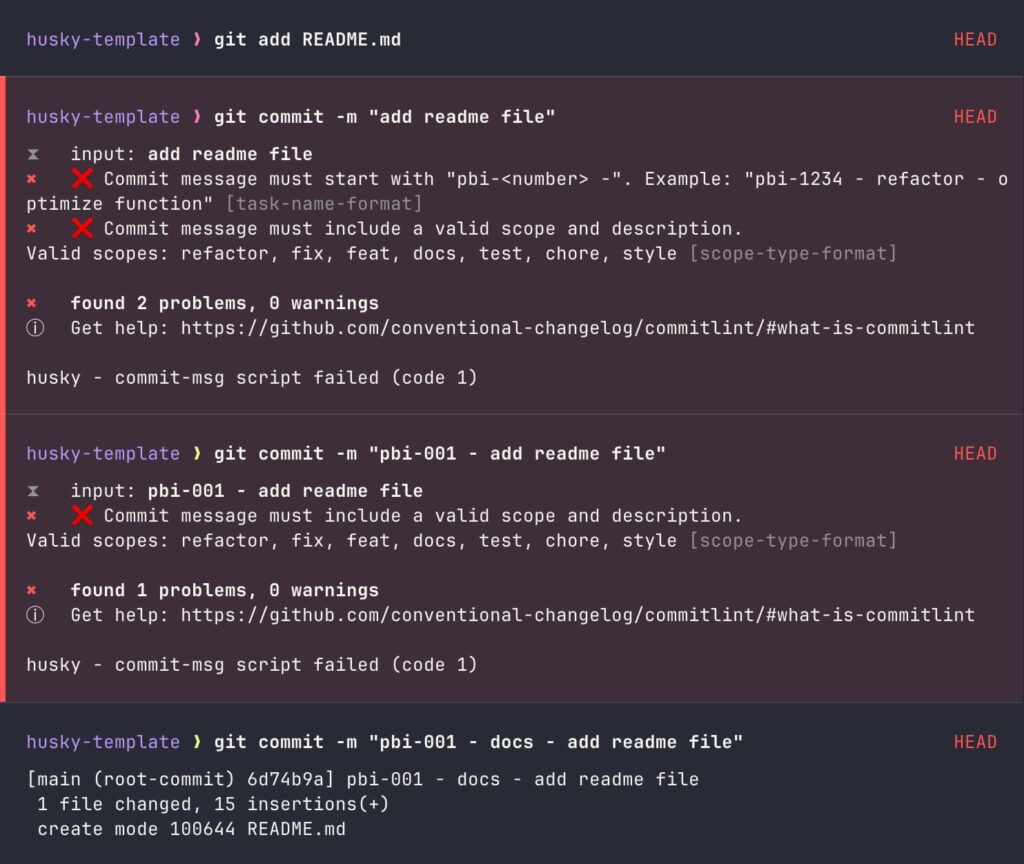
Now, developers will be forced to follow this committing rule, which increases the readability of the Git History.
Automate Branch Naming Conventions
Enforce branch names like feature/pbi-199/add-validation.
- First, we will create a script in the project directory named scripts/check-branch-name.sh.
#!/bin/bash # Define allowed branch naming pattern branch_pattern="^(feature|bugfix|hotfix|release)/pbi-[0-9]+/[a-zA-Z0-9._-]+$" # Get the current branch name current_branch=$(git symbolic-ref --short HEAD) # Check if the branch name matches the pattern if [[ ! "$current_branch" =~ $branch_pattern ]]; then echo "❌ Branch name '$current_branch' is invalid!" echo "✅ Branch names must follow this pattern:" echo " - feature/pbi-<number>/<description>" echo " - bugfix/pbi-<number>/<description>" echo " - hotfix/pbi-<number>/<description>" echo " - release/pbi-<number>/<description>" exit 1 fi echo "✅ Branch name '$current_branch' is valid."
- Add the above script execution command into the pre-push hook.
echo "bash ./scripts/check-branch-name.sh" >> .husky/pre-push
- Grant execute permissions to the check-branch-name.sh file.
chmod +x ./scripts/check-branch-name.sh
- Let’s test the result by pushing our code to the server.
Invalid case:
git checkout main git push
Output:
❌ Branch name 'main' is invalid! ✅ Branch names must follow this pattern: - feature/pbi-<number>/<description> - bugfix/pbi-<number>/<description> - hotfix/pbi-<number>/<description> - release/pbi-<number>/<description> husky - pre-push script failed (code 1)
Valid case:
git checkout -b feature/pbi-100/add-new-feature git push
Output:
✅ Branch name 'feature/pbi-100/add-new-feature' is valid.
Prevent Accidental Force Pushes
Force pushes can overwrite shared branch history, causing significant problems in collaborative projects. We will implement validation for the prior pre-push hook to prevent accidental force pushes to critical branches like main or develop.
- Create a script named scripts/prevent-force-push.sh.
#!/bin/bash
# Define the protected branches
protected_branches=("main" "develop")
# Get the current branch name
current_branch=$(git symbolic-ref --short HEAD)
# Check if the current branch is in the list of protected branches
if [[ " ${protected_branches[@]} " =~ " ${current_branch} " ]]; then
# Check if the push is a force push
for arg in "$@"; do
if [[ "$arg" == "--force" || "$arg" == "-f" ]]; then
echo "❌ Force pushing to the protected branch '${current_branch}' is not allowed!"
exit 1
fi
done
fi
echo "✅ Push to '${current_branch}' is valid."
- Add the above script execution command into the pre-push hook.
echo "bash ./scripts/prevent-force-push.sh" >> .husky/pre-push
- Grant execute permissions to the check-branch-name.sh file.
chmod +x ./scripts/prevent-force-push.sh
- Result:
Invalid case:
git checkout main git push -f
Output:
❌ Force pushing to the protected branch 'main' is not allowed! husky - pre-push script failed (code 1)
Valid case:
git checkout main git push
Output:
✅ Push is valid.
Monitor for Secrets in Commits
Developers sometimes unexpectedly include sensitive data in commits. We will set up a pre-commit hook to scan files for sensitive patterns before committing to prevent accidental commits containing sensitive information (such as API keys, passwords, or other secrets).
- Create a script named scripts/monitor-secrets-with-values.sh.
#!/bin/bash
# Define sensitive value patterns
patterns=(
# Base64-encoded strings
"([A-Za-z0-9+/]{40,})={0,2}"
# PEM-style private keys
"-----BEGIN RSA PRIVATE KEY-----"
"-----BEGIN OPENSSH PRIVATE KEY-----"
"-----BEGIN PRIVATE KEY-----"
# AWS Access Key ID
"AKIA[0-9A-Z]{16}"
# AWS Secret Key
"[a-zA-Z0-9/+=]{40}"
# Email addresses (optional)
"[a-zA-Z0-9._%+-]+@[a-zA-Z0-9.-]+\.[a-zA-Z]{2,}"
# Others (e.g., passwords, tokens)
)
# Scan staged files for sensitive patterns
echo "🔍 Scanning staged files for sensitive values..."
# Get the list of staged files
staged_files=$(git diff --cached --name-only)
# Initialize a flag to track if any sensitive data is found
found_sensitive_data=false
# Loop through each file and pattern
for file in $staged_files; do
# Skip binary files
if [[ $(file --mime-type -b "$file") == "application/octet-stream" ]]; then
continue
fi
# Scan each pattern using grep -E (extended regex)
for pattern in "${patterns[@]}"; do
if grep -E -- "$pattern" "$file"; then
echo "❌ Sensitive value detected in file '$file': Pattern '$pattern'"
found_sensitive_data=true
break
fi
done
done
# If sensitive data is found, prevent the commit
if $found_sensitive_data; then
echo "❌ Commit aborted. Please remove sensitive values before committing."
exit 1
fi
echo "✅ No sensitive values detected. Proceeding with committing."
- Add the above script execution command into the pre-commit hook.
echo "bash ./scripts/monitor-secrets-with-values.sh" >> .husky/pre-commit
- Grant execute permissions to the monitor-secrets-with-values.sh file.
chmod +x ./scripts/monitor-secrets-with-values.sh
- Result:
Invalid case:
git add private git commit -m “pbi-002 - chore - add unexpected private file”
Result:
🔍 Scanning staged files for sensitive values... -----BEGIN OPENSSH PRIVATE KEY----- ❌ Sensitive value detected in file 'private': Pattern '-----BEGIN OPENSSH PRIVATE KEY-----' ❌ Commit aborted. Please remove sensitive values before committing. husky - pre-commit script failed (code 1)
Valid case:
git reset private git commit -m “pbi-002 - chore - remove unexpected private file”
Result:
🔍 Scanning staged files for sensitive values... ✅ No sensitive values detected. Proceeding with commit. [main c575028] pbi-002 - chore - remove unexpected private file 4 files changed, 5 insertions(+) create mode 100644 .env.example create mode 100644 .husky/commit-msg create mode 100644 .husky/pre-commit create mode 100644 .husky/pre-push
Conclusion
“Humans make mistakes” in software development; even minor errors can disrupt workflows or create inefficiencies. That’s where Git Hooks come in. By automating essential checks and enforcing best practices, Git Hooks reduces the chances of errors slipping through and ensures a smoother, more consistent workflow.
Tools like Husky make it easier to set up Git Hooks, allowing developers to focus on writing code instead of worrying about process compliance. Whether it’s validating commit messages, enforcing branch naming conventions, or preventing sensitive data from being committed, Git Hooks acts as a safety net that ensures quality at every step.
If you want to optimize your Git workflow, now is the time to start integrating Git Hooks. With the proper setup, you can make your development process reliable but also effortless and efficient. Let automation handle the rules so your team can focus on building great software.